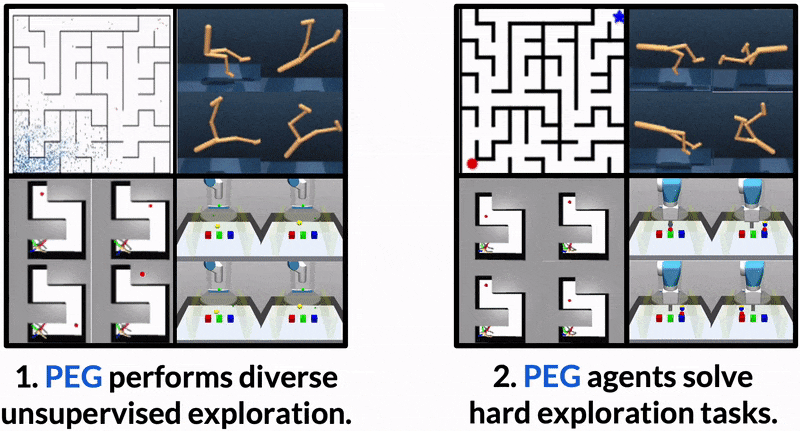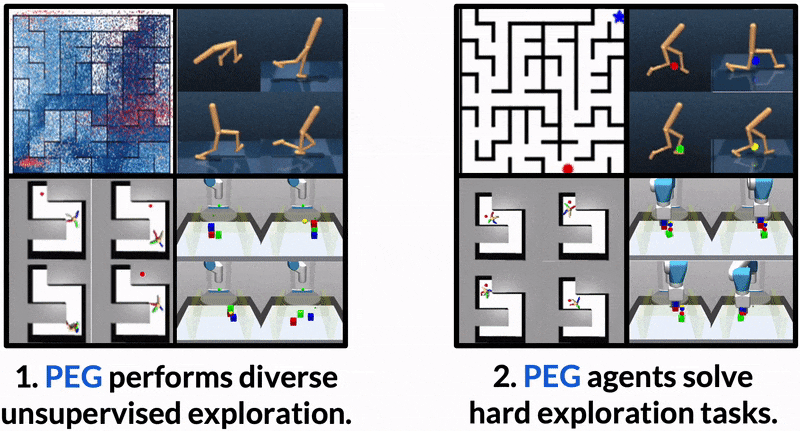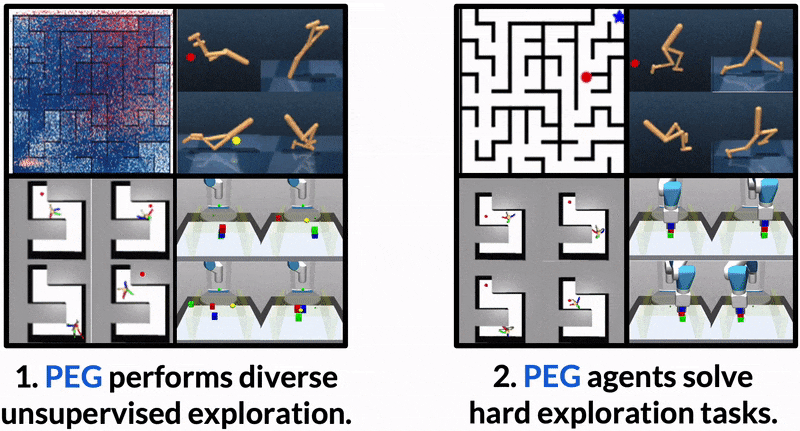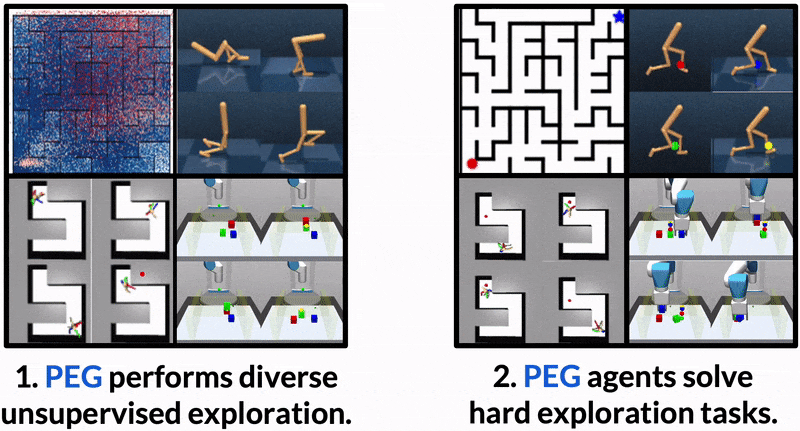
Dropped into an unknown environment, what should an agent do to quickly learn about the environment and how to accomplish diverse tasks within it?
We address this question within the goal-conditioned reinforcement learning paradigm, by identifying how the agent should set its goals at training time to maximize exploration. We propose "planning exploratory goals" (PEG), a method that sets goals for each training episode to directly optimize an intrinsic exploration reward.
PEG first chooses goal commands such that the agent's goal-conditioned policy, at its current level of training, will end up in states with high exploration potential. It then launches an exploration policy starting at those promising states. To enable this direct optimization, PEG learns world models and adapts sampling-based planning algorithms to "plan goal commands". In challenging simulated robotics environments including a multi-legged ant robot in a maze, and a robot arm on a cluttered tabletop, PEG exploration enables more efficient and effective training of goal-conditioned policies relative to baselines and ablations. Our ant successfully navigates a long maze, and the robot arm successfully builds a stack of three blocks upon command
PEG's superior evaluation performance is attributed to its sophisticated exploration, which enables the agent to learn from more informative data. PEG learns complex skills like cartwheeling in the walker environment, obstacle navigation in the ant maze, and stacking in the block environment all through an unsupervised exploration objective.
@inproceedings{
hu2023planning,
title={Planning Goals for Exploration},
author={Edward S. Hu and Richard Chang and Oleh Rybkin and Dinesh Jayaraman},
booktitle={The Eleventh International Conference on Learning Representations },
year={2023},
url={https://openreview.net/forum?id=6qeBuZSo7Pr}
}