Abstract
How can we pre-train and fine-tune a multi-modal representation suitable for language-conditioned robotics manipulation and reward specification?
We present Language-Image Value learning (LIV), a unified objective for vision-language representation and reward learning from action-free videos with text annotations. Exploiting a novel connection between dual reinforcement learning and mutual information contrastive learning, LIV proposes a simple and effective objective that learns a multi-modal representation that implicitly encodes a goal-conditioned value function that can express goals in all modalities. We use LIV to pre-train the first control-centric vision-language representation from large human video datasets such as EpicKitchen with no action information. This pre-trained LIV model can perform zero-shot language-conditioned reward specification on unseen human and robot videos alike. Then, with access to target domain data, the very same objective consistently improves this pre-trained LIV model as well as other pre-existing vision-language representations for improved language-conditioned reward specification and robotic control. On two simulated and one real-world robot environments that evaluate vision-language representations and rewards, LIV pre-trained and fine-tuned models consistently outperform the best prior approaches, establishing the advantages of joint vision-language representation and reward learning within its unified, compact framework.
Video (Short Teaser)
Video
LIV Zero-Shot Multi-Modal Reward
Unseen Human Videos
Unseen Robot Videos
LIV Reward for Action Recognition
How can I generate LIV reward curves on my own videos?
Failure Cases
LIV as Representation for Language-Conditioned BC
Environment Description
Pineapple in Black Pot (8/10)
Pineapple in Green Pot (6/10)
Pineapple in Tray (5/10)
Apple in Black Pot (4/10)
Apple in Green Pot (3/10)
Apple in Tray (5/10)
Pear in Black Pot (4/10)
Pear in Green Pot (3/10)
Pear in Tray (3/10)
Zero-Shot Generalization to Long-Horizon Composite Tasks
LIV Few-Shot Fine-Tuning
LIV Multi-Modal Reward Comparison (Pre-Trained vs. Fine-Tuned)
LIV (Pre-Trained)
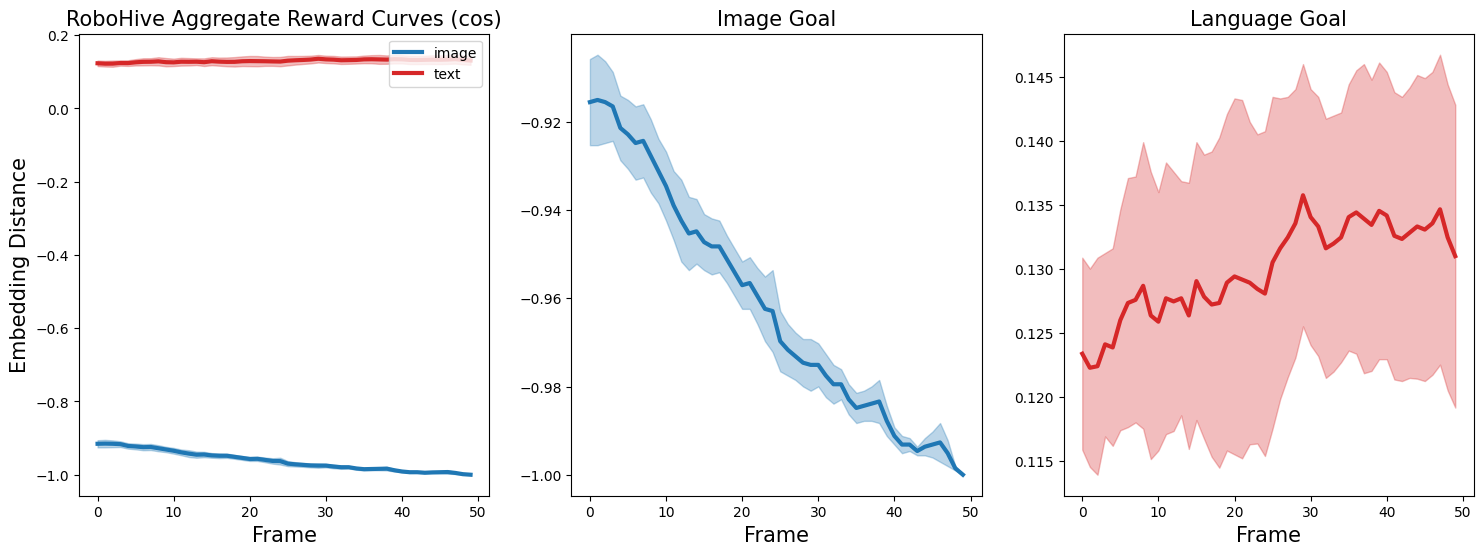
LIV (LIV Fine-Tuned)
LIV LCBC Comparison (Pre-Trained vs. Fine-Tuned)
LIV (Pre-Trained)
LIV (LIV Fine-Tuned)
BibTeX
@article{ma2023liv,
title={LIV: Language-Image Representations and Rewards for Robotic Control},
author={Ma, Yecheng Jason and Liang, William and Som, Vaidehi and Kumar, Vikash and Zhang, Amy and Bastani, Osbert and Jayaraman, Dinesh},
journal={arXiv preprint arXiv:2306.00958},
year={2023}
}